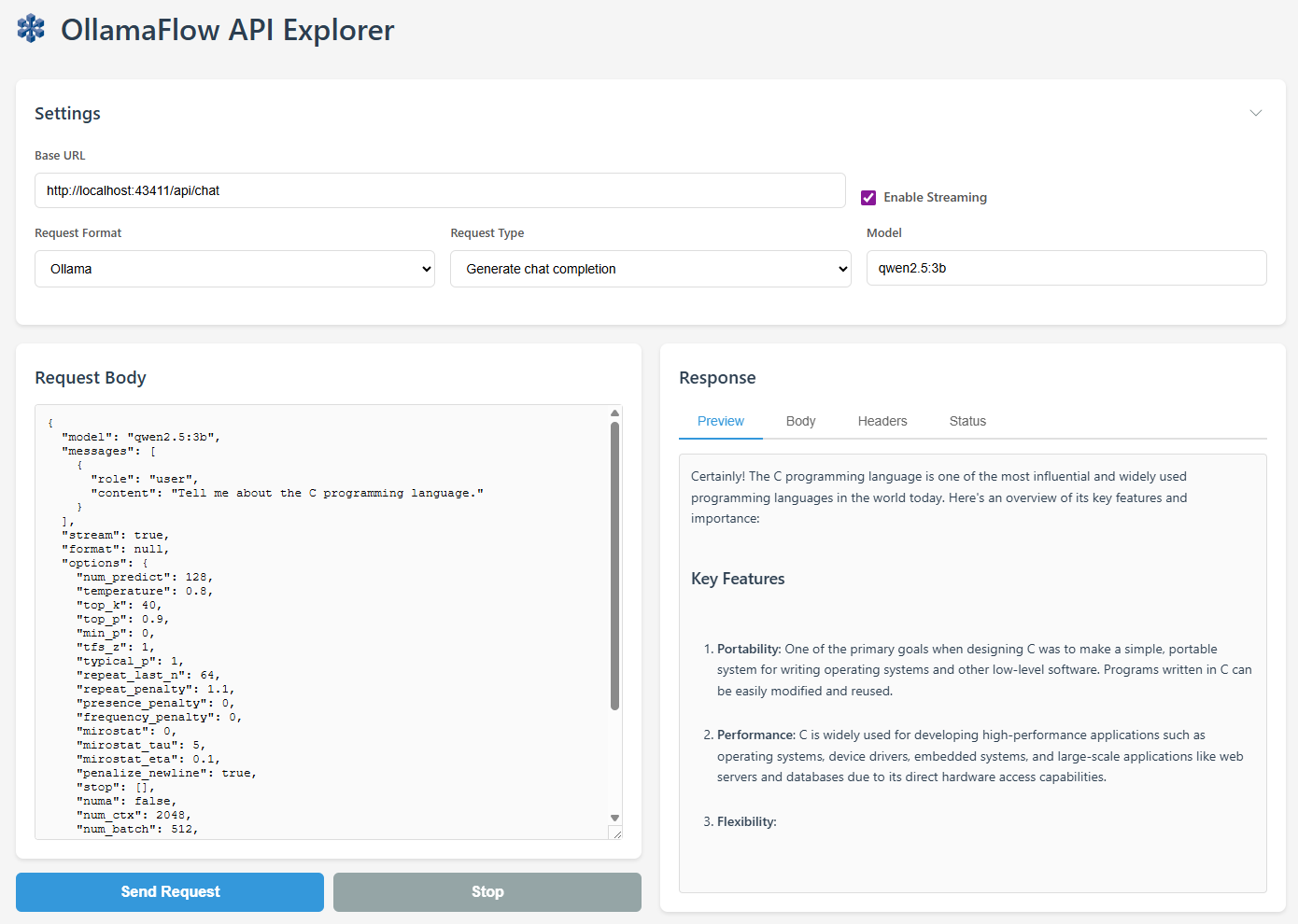
API Explorer
Test and Validate Your APIs
The OllamaFlow API Explorer is a web-based tool designed for testing, debugging, and evaluating AI inference APIs in a browser-based experience.
- Support for Ollama and OpenAI API formats
- Real-time API testing with streaming support
- JSON syntax validation
- Response body and header inspection
- Load testing capabilities